

デジタルメディアの進化は私たちの創造性に無限の可能性をもたらしています。
特に、テキストを音声に変換する技術は、情報のアクセス方法を根本から変えつつあります。
llElevenLabsは、この技術の最前線に立ち、驚くほど自然な音声を生成することで、コンテンツ制作者が新しい形の表現を探求できる道を開いています。
本記事では、llElevenLabsの概要とその圧倒的な機能を紹介し、あなたがどのようにしてこのツールを最大限に活用できるかを掘り下げていきます。
読み進めることで、あなたのプロジェクトがどのように変わるかを見てみましょう。
はじめに:llElevenLabsの概要
llElevenLabsは、革新的なテキストから音声への変換サービスを提供するプラットフォームです。
このツールを使用すると、ユーザーは自然な音声を生成し、異なる言語やアクセントでテキストをオーディオ化できます。
その応用範囲はオーディオブック、ポッドキャスト制作、ビデオナレーションなど多岐にわたります。
この記事では、llElevenLabsの基本機能を解説し、その使用方法を具体的に学ぶことを目的としています。
読者がプラットフォームを効果的に活用し、ビジネスにどのように役立てるかを重点おきに、llElevenLabsを使いこなすための実践的なガイドとして機能することを願っています。
なお、このツールを使えれば、自分のアバターに話させることもできますの。アバターとのコラボについては別の記事で紹介しようと思います。
アカウント設定とダッシュボードの基本操作
ここからはllElevenLabsの具体的な使い方について紹介します。
アカウント登録
まずはllElevenLabsのホームページ(https://elevenlabs.io)へアクセスし、右上の「Sign up」からアカウント登録をします。
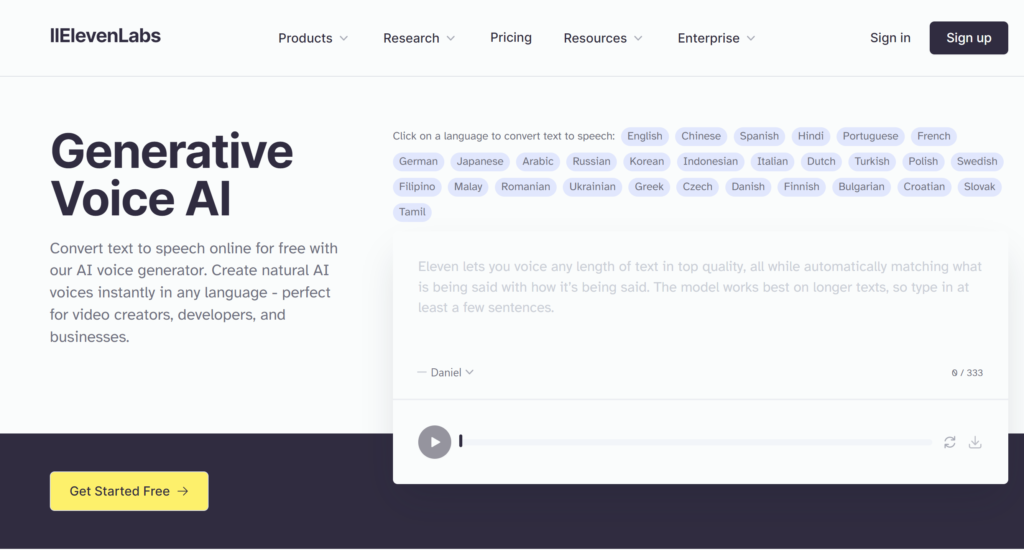
サインアップ画面にてサインアップを行いましょう。Googleアカウントまたはメールアドレスでの登録になります。
ダッシュボード画面が表示されればアカウント登録は完了です。
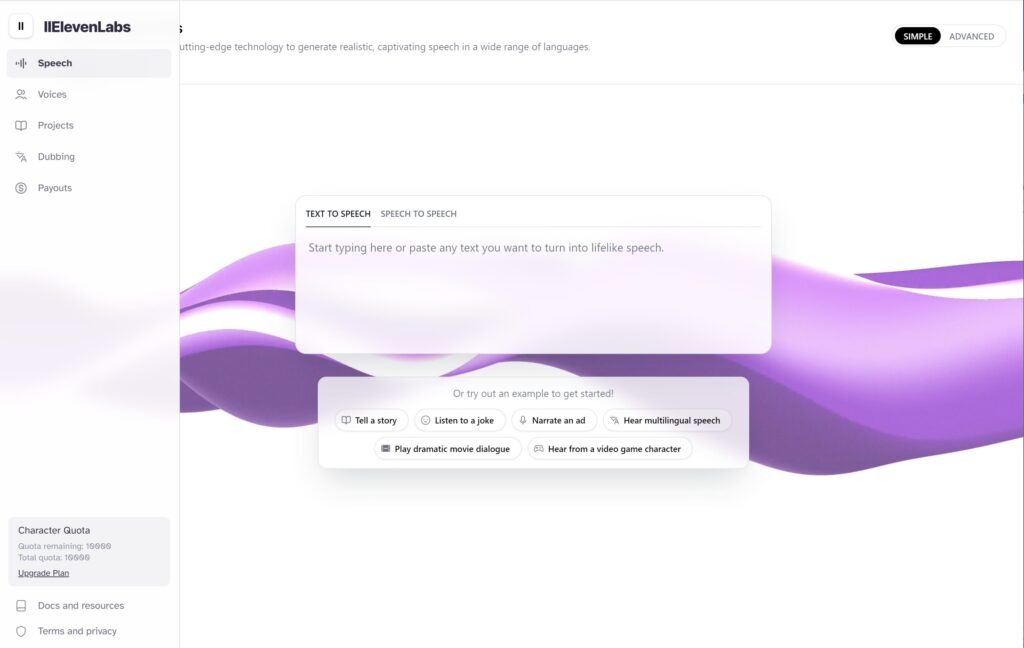
ダッシュボードの基本操作
ダッシュボードには以下の要素が配置されており、それぞれ何ができるかを簡単に説明します。
- speech : テキストからスピーチを作成できます。
- Voices:音声化するための基となる声を作成します。
- Porjects:プロジェクトとして文章や音声編集ファイルを管理できます。
- Dubbing:様々なコンテンツ(ファイル、SNSから音声源をインポートし、他言語に変換したりできます。
- Payouts:支払いに関する設定です。
【Speech】テキストから音声への変換
ここではSpeechの機能でテキストから音声を生成してみます。
メニューバーから「Speech」を選択し、「Speech Synthesis」画面へ移動しましょう。
スピーチに変換したいテキストの入力
画面中央に「TEXT TO SPEECH」が存在するので、枠内にスピーチに変換したいテキストを入力します。
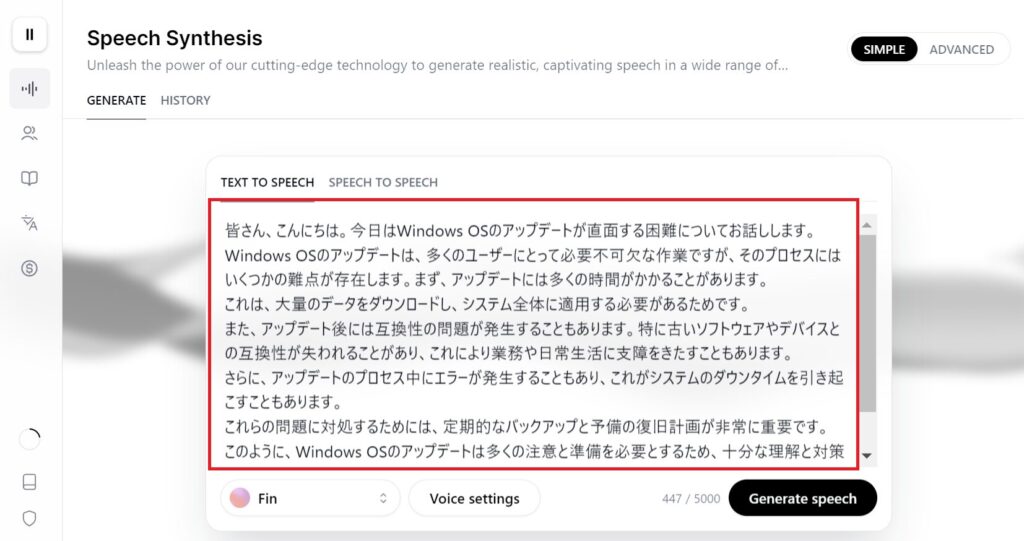
サンプル音声の設定
左下のボタンからボイスサンプルを選択できます。女性の名前は女の人の声を表し、男性名は男の人の声を表しています。
今回はサンプルとしてフィンを選択しました。
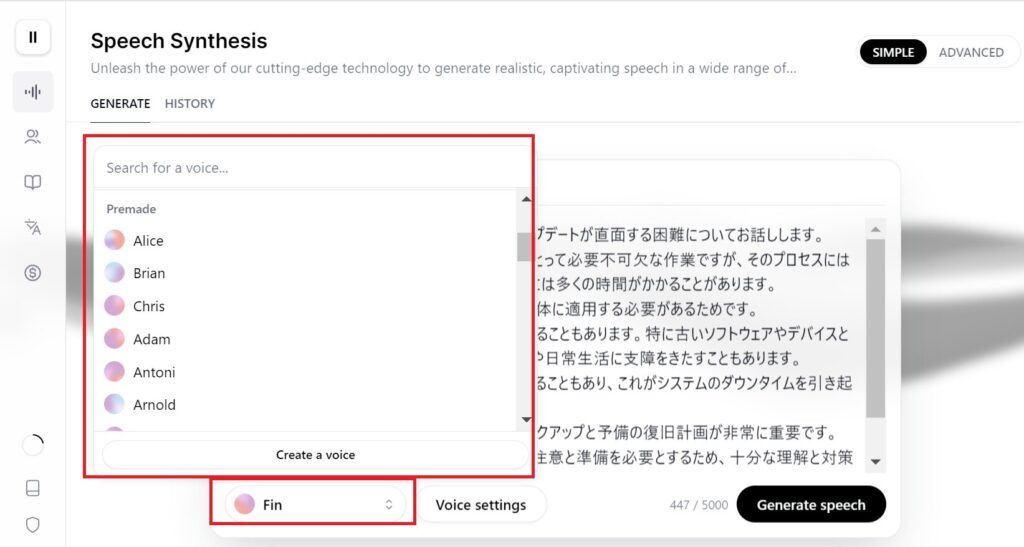
サンプル音声からのカスタマイズ
選択したサンプル音声をカスタマイズすることができます。
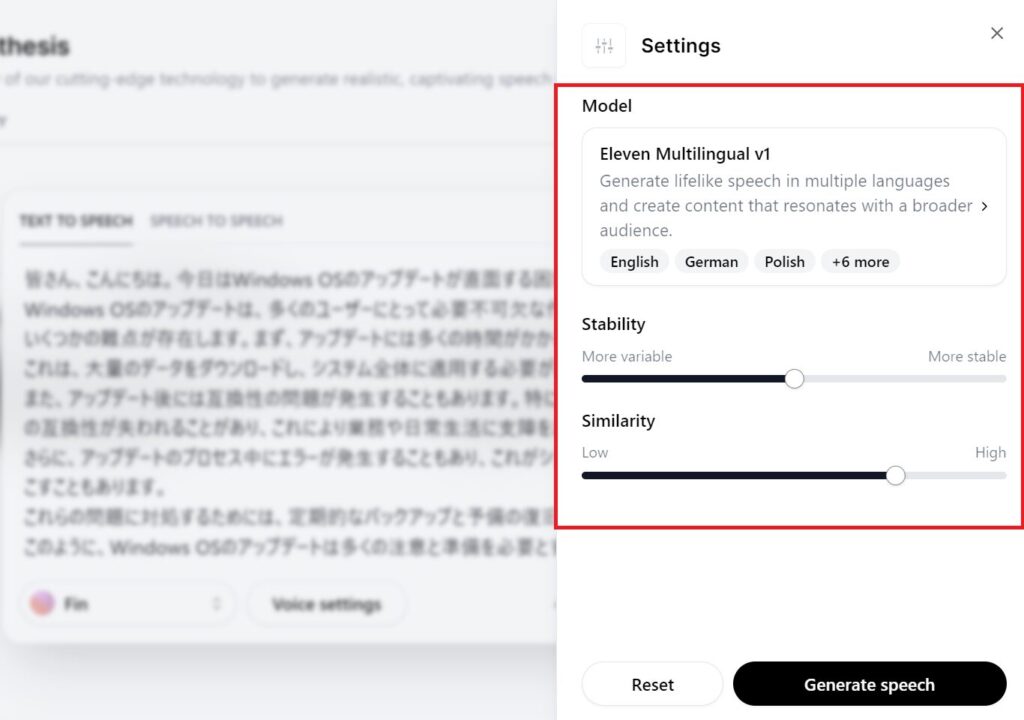
カスタマイズするには「Voice settings」という真ん中下あたりのボタンを選択します。
すると以下のようにSettingsウィンドウが開きます。これが”フィン”の設定値のようです。
日本語よ読み上げるには「Model」を「Eleven Multilingual v2」に変更しておきましょう。(v1では日本語には対応していません。)

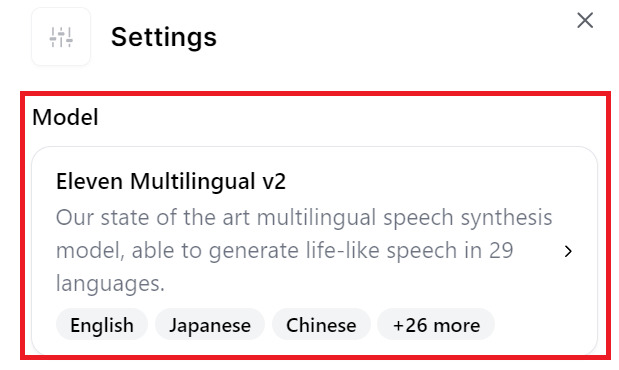
設定を行っていきます。設定画面は以下のようなものです。
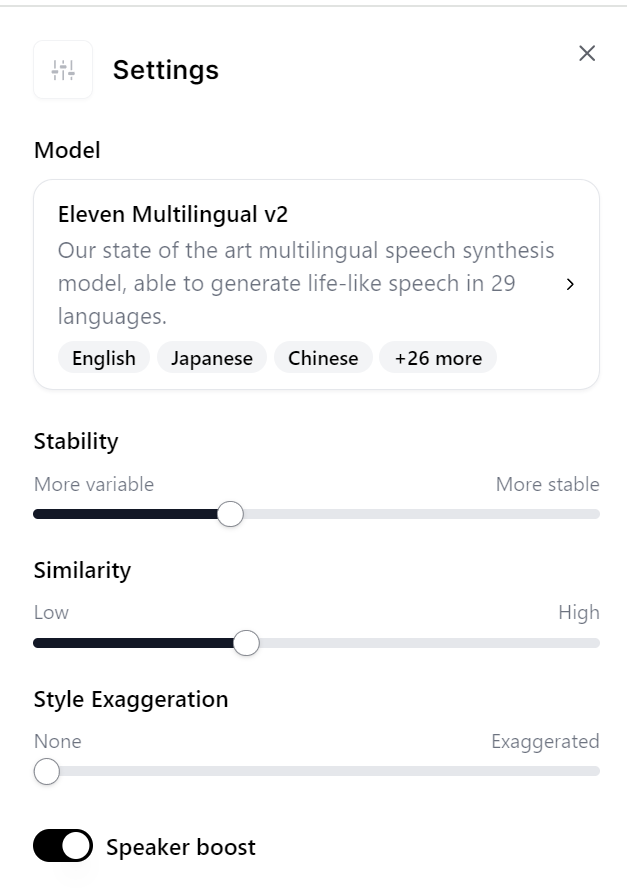
パラメータの説明を簡単にします。
【Stability】
「Stability」は声の安定性です。variableは変化なので、言い換えれば声の抑揚についてだと思われます。
- More variable:変化のしやすさ
- More stable:安定のしやすさ
【Similatity】
「Similatity」は声の類似性です。サンプル音声に対する類似性のことだと思われます。
サンプル音声の元がわからないため、基本はデフォルト設定でよいと考えます。
自分の声や外部からインポートした音声に対して類似性を持たせるかを決めたい場合に重要視するパラメータだと思います。
【Style Exaggration】
Exaggrationは誇張表現です。
どのような場合に誇張するのか、いまいち不明ですので検証は必要です。
サンプルしたテキスト
サンプルスピーチを作るために使用するのは、WindowsOSアップデートに関する難しさを題材にしたテキストです。ChatGPTで生成しました。
皆さん、こんにちは。
今日はWindows OSのアップデートが直面する困難についてお話しします。
Windows OSのアップデートは、多くのユーザーにとって必要不可欠な作業ですが、そのプロセスにはいくつかの難点が存在します。
まず、アップデートには多くの時間がかかることがあります。
これは、大量のデータをダウンロードし、システム全体に適用する必要があるためです。
また、アップデート後には互換性の問題が発生することもあります。
特に古いソフトウェアやデバイスとの互換性が失われることがあり、これにより業務や日常生活に支障をきたすこともあります。さらに、アップデートのプロセス中にエラーが発生することもあり、これがシステムのダウンタイムを引き起こすこともあります。
これらの問題に対処するためには、定期的なバックアップと予備の復旧計画が非常に重要です。
このように、Windows OSのアップデートは多くの注意と準備を必要とするため、十分な理解と対策が求められるのです。
どうぞご留意ください。
サンプル音声①:Stability:低め、Similarity:低め
以下のような設定を行っています。
Stability:低め (40程度)
Similarity:低め(40程度)
Style Exaggration:なし(0)
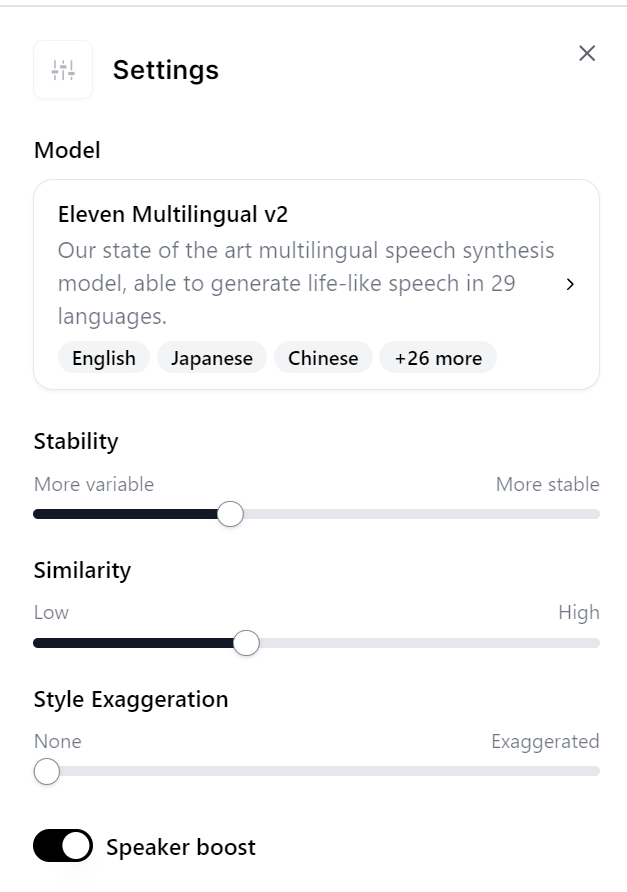
日本語を話せる外国人が話しているような感覚です。抑揚は少し控えめです。
サンプル音声②:Stability:高め、Similarity:高め
以下のような設定を行っています。
Stability:高め (ほぼMAX)
Similarity:高め(ほぼMAX)
Style Exaggration:なし(0)
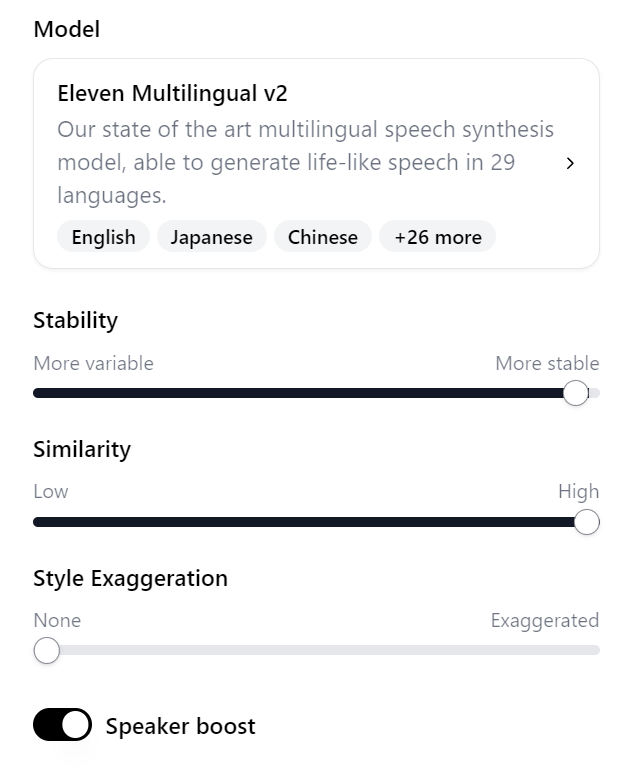
こちらも日本語を話せる外国人が話しているような感覚ですが、①のサンプルよりも抑揚をつけようとしている感覚があります。
サンプル音声③:Style Exaggration:高め
わざとStyle Exaggrationを高めに設定してみました。(”Over 50% may lead to instablity”とエラーっぽいものが出ていますが一旦無視します。
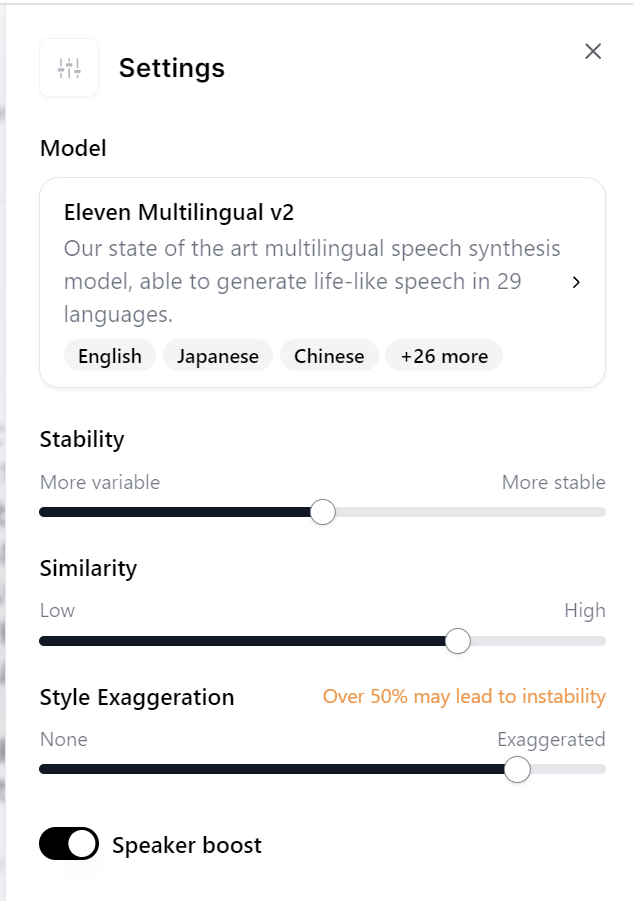
なんだか誇張表現をしようとしすぎたのか、0:50あたりで音声が途中で変になったりしてます。「~や~、~え~」などが伸ばしたりと誇張表現されています。
パラメータの調整は検証してみる必要がありそうです。
いずれにせよ、サンプル音声は日本からすると海外サンプルになるので、日本語に当てはめようとすると少し訛った感じは否めません。
しかし、ロボットのような感覚はありません。海外出身のコメディアンが話すように流暢に聞こえます。
【Voices】声の音源をカスタマイズ
ここからは声の音源をカスタマイズしてみます。
サンプル音声からいくつかの設定変更が可能です。
VoiceLabで音声カスタマイズ(Voice Design:無料)
「VoiceLab」を選択し、真ん中の「+」ボタンをクリックします。
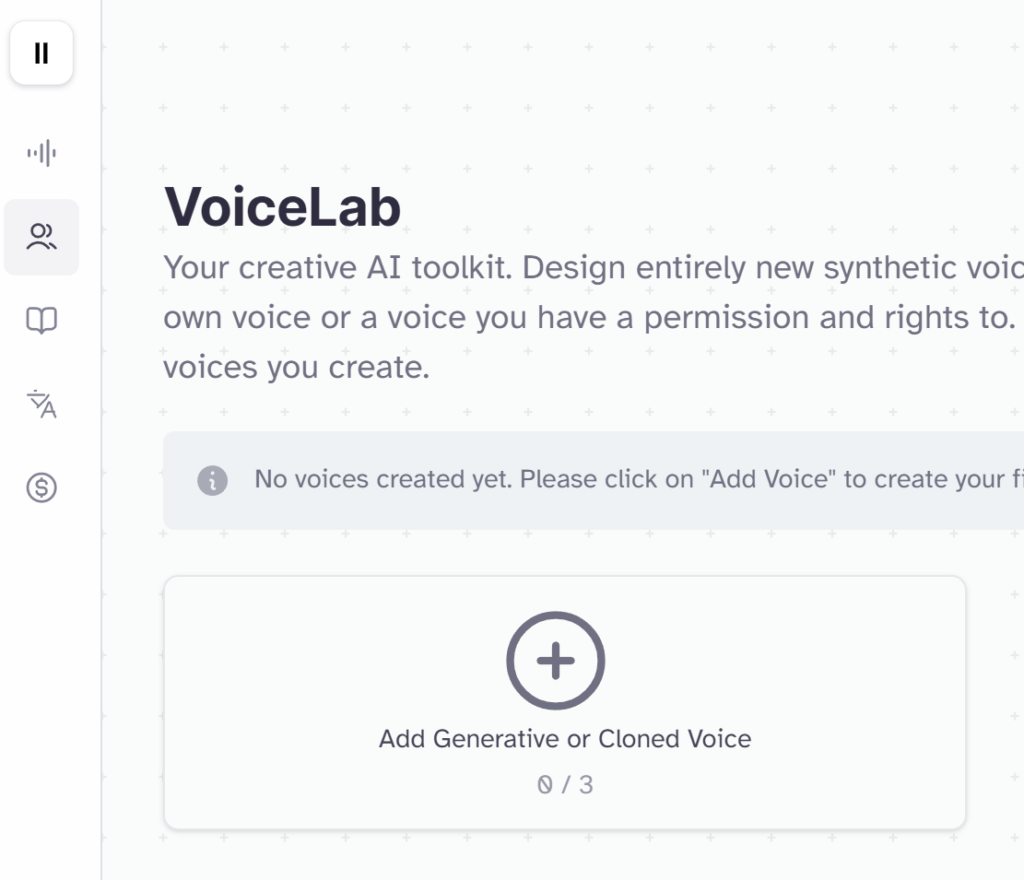
ここでは4種類の音源生成ができますが、無料で利用できる「Voice Design」をクリックします。
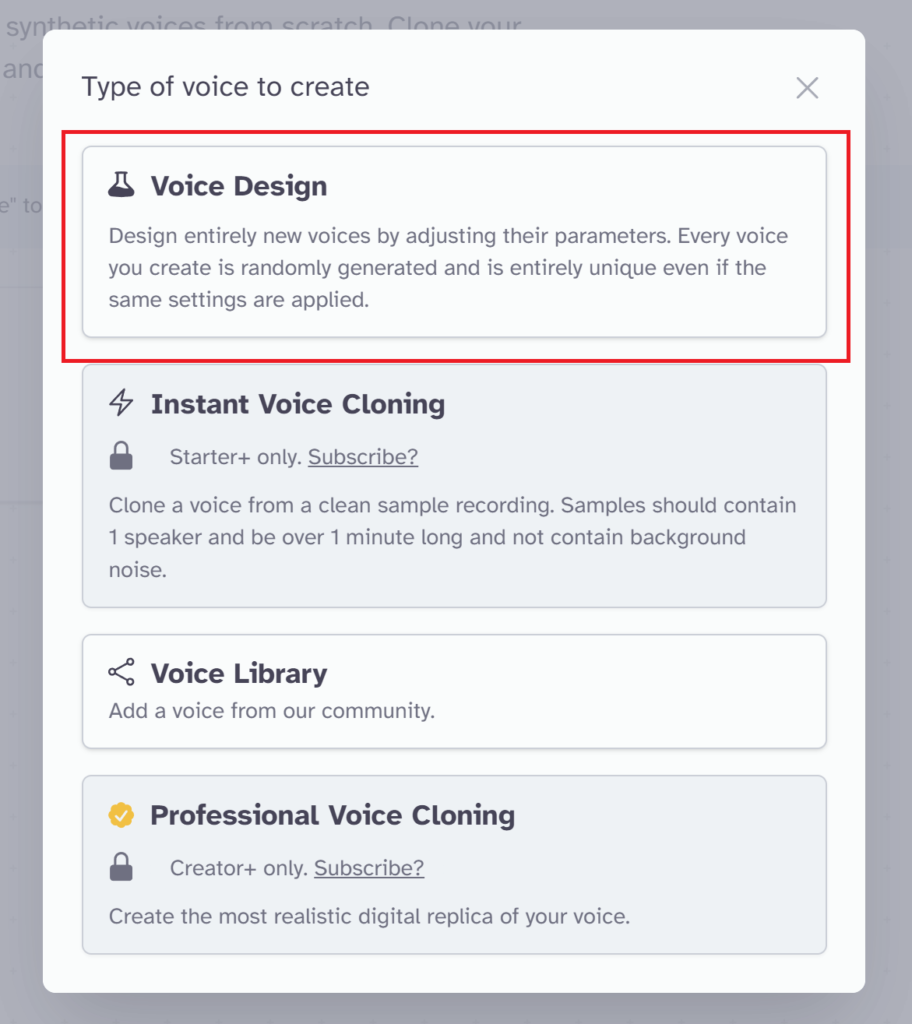
Voice Designではプルダウン式で音源をカスタマイズしていきます。
【パラメータ】
Gender:Mail / Femail
Age:Young / Middle Aged / Old
Accent
Accent Strength:Low ~ High
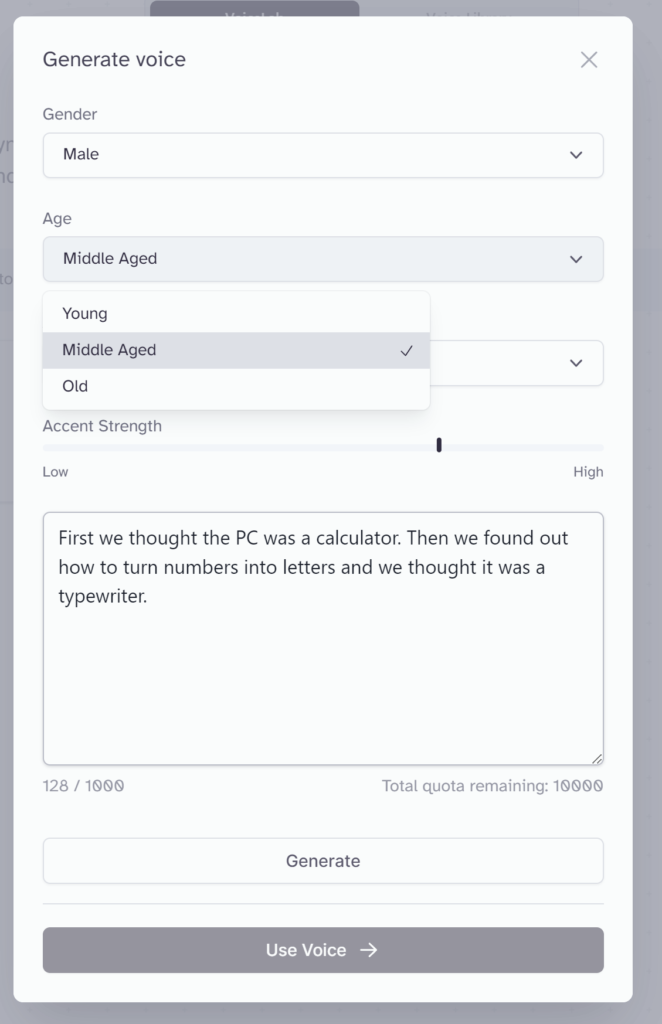
(Ageの例)
(Accentの例)AccentではAmericanやBritish、Africanなど人種を選択できるみたいです。
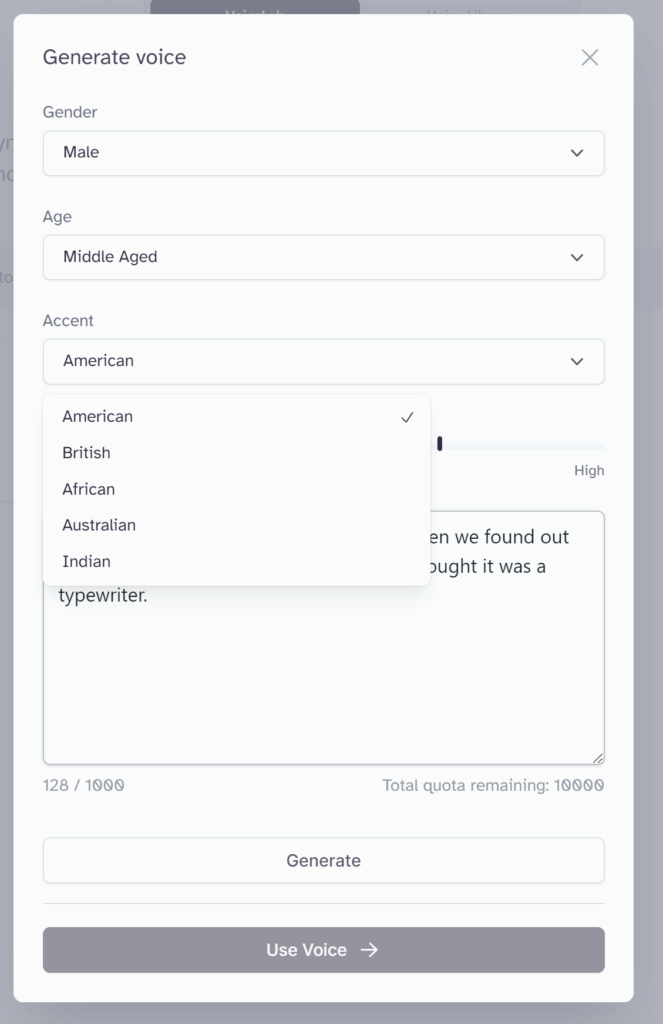
サンプルとしては「American、Middle Aged、Mail」を選択しました。
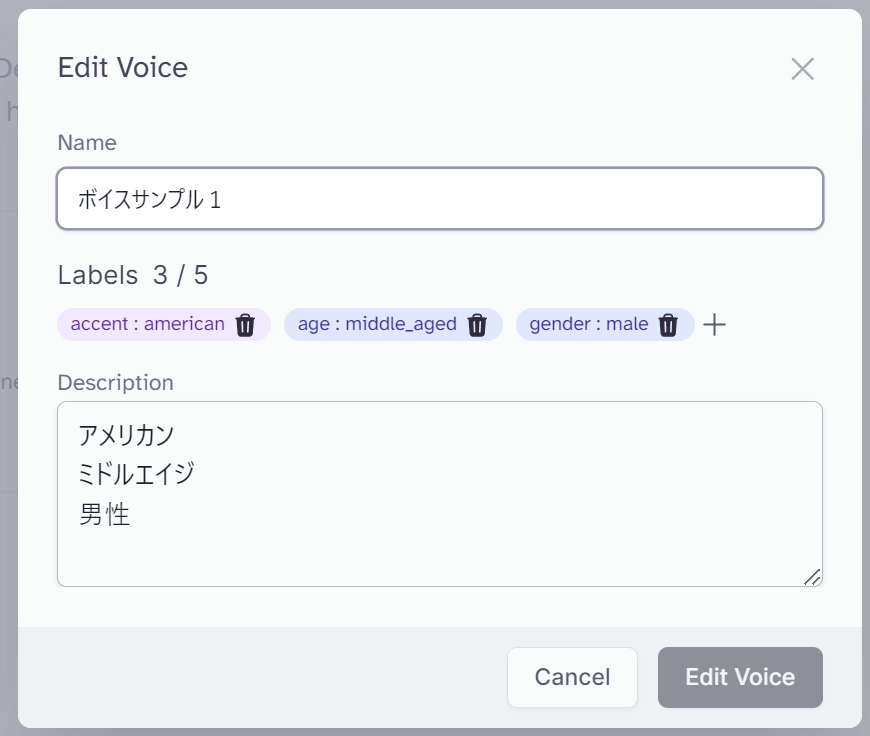
サンプルとして、先ほどSpeechで実践したテキストからスピーチに音声化する機能で、サンプル音声を生成してみました。
英語ではないのでAmericanかはわかませんが、ミドルエイジ、男性という観点では当てはまっています。
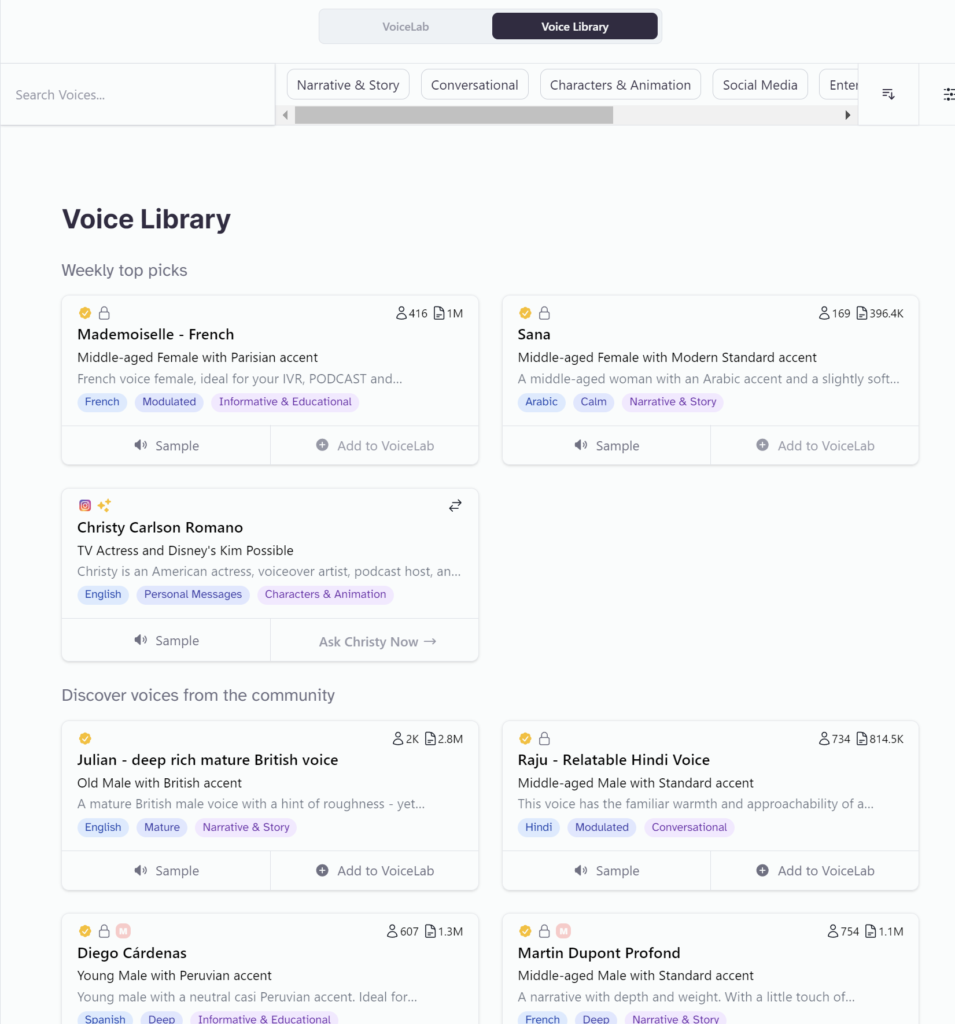
ライブラリからサンプル音声を使用する(Voice Library:無料)
無料で使える機能としてVoice Libraryがあります。「Voice Lab」の「+」マークから「Voice Library」を選択します。
すると様々なサンプルが用意されています。
ここでサンプルをチェックをして、気に入った音声があれば「Add to Voice」から、VoiceLabに追加できます。
ただし、「鍵マーク」があるものは、一定の有料プランでないと追加できないので注意が必要です。
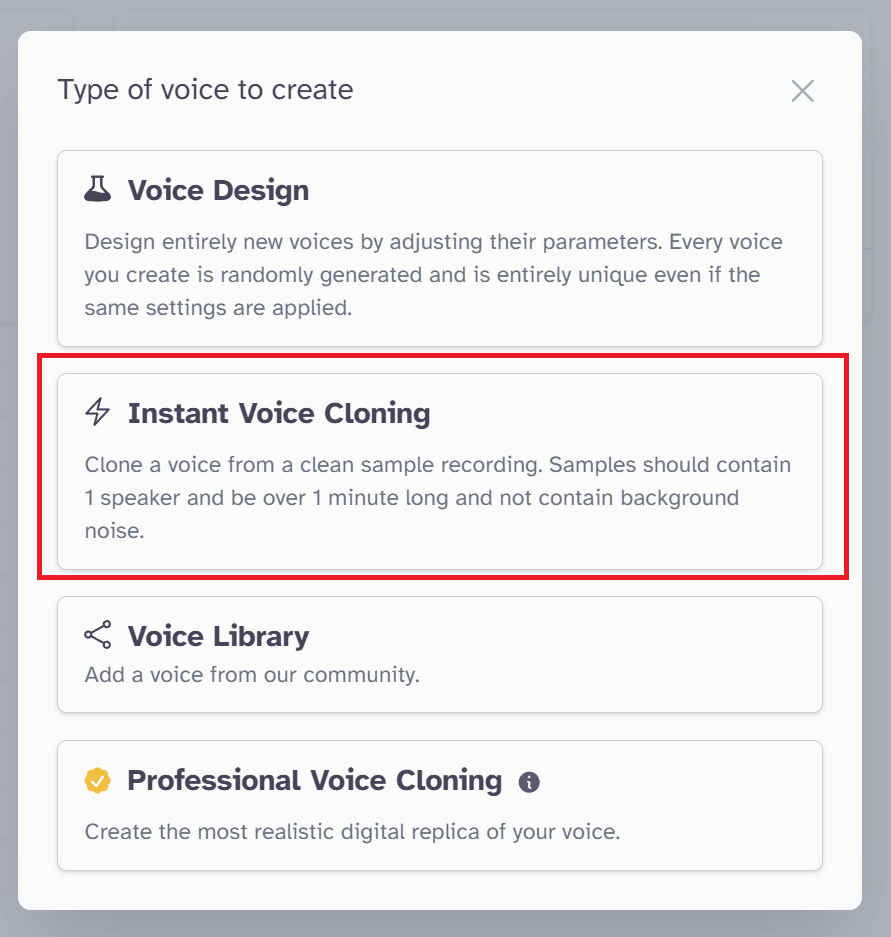
VoiceLabで自分の声から音源作成(Instant Voice Cloning:有料)
ここからは有料プランです。最低”Starter”以上のプランに加入が必要です。
VoiceLabの「Instant Voice Cloning」では、音源をインポートして、その音源をもとに別のテキストからスピーチさせることができます。
まずは「Voice Lab」の「+」マークから「Instant Voice Cloning」を選択します。
次に「Name」にこの音声を識別する名前を入力。
「Click to upload a file or drag and drop」欄から、自分が音源にしたい音声ファイルをアップロードします。
下のチェックボックスにチェックを入れ、「Add Voice」ボタンをクリックします。
VoiceLab画面に遷移します。これで音源の登録が完了です。「Use」ボタンからSpeech機能へ移動できます。
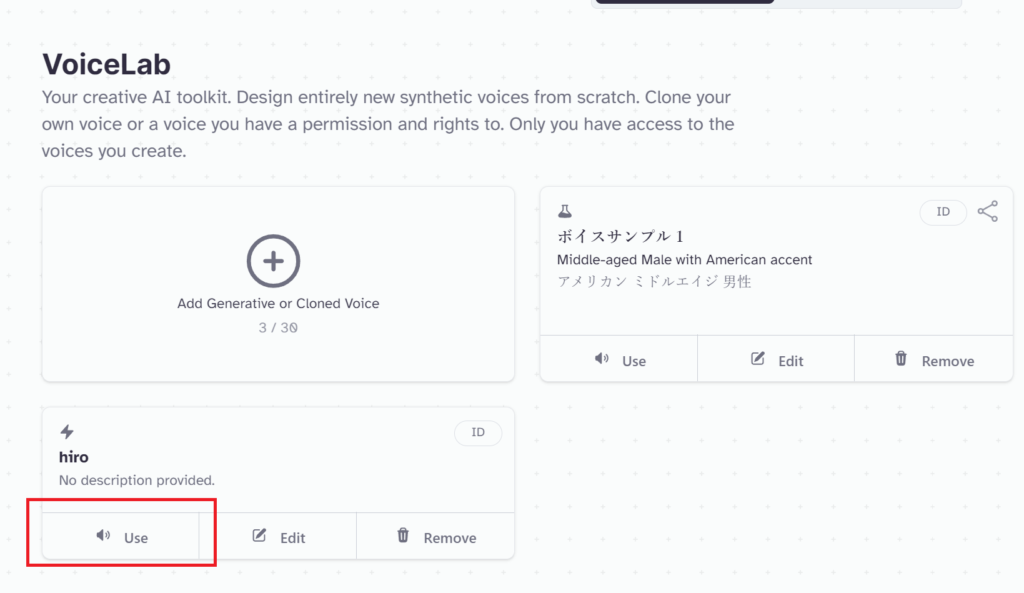
あとはSpeech機能になるので、読ませたいテキストを記載して「Generate speech」ボタンを押しましょう。
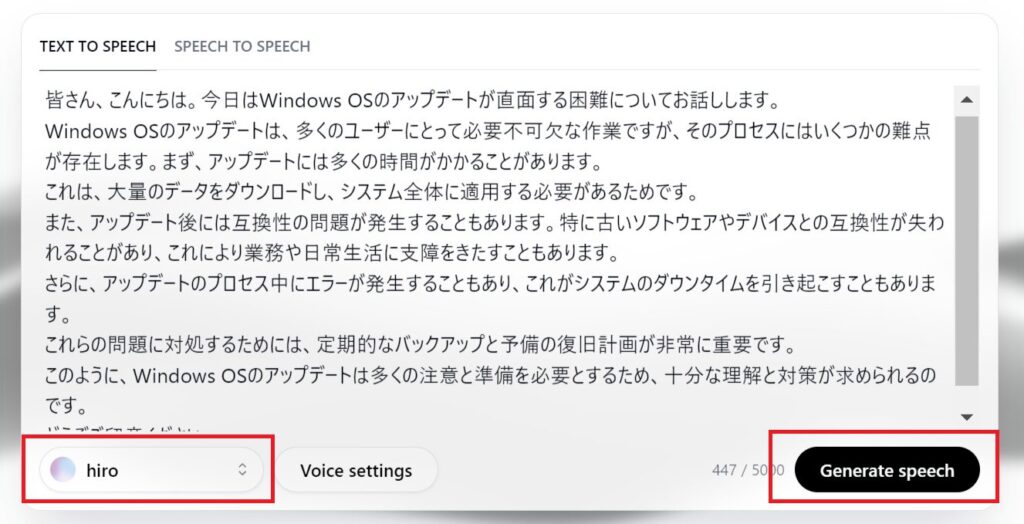
サンプル音声は画面したに表示され、「↓」よりダウンロードが可能です。

以上が、Instant Voice Cloning機能でした。Instantというだけとても簡単でした。
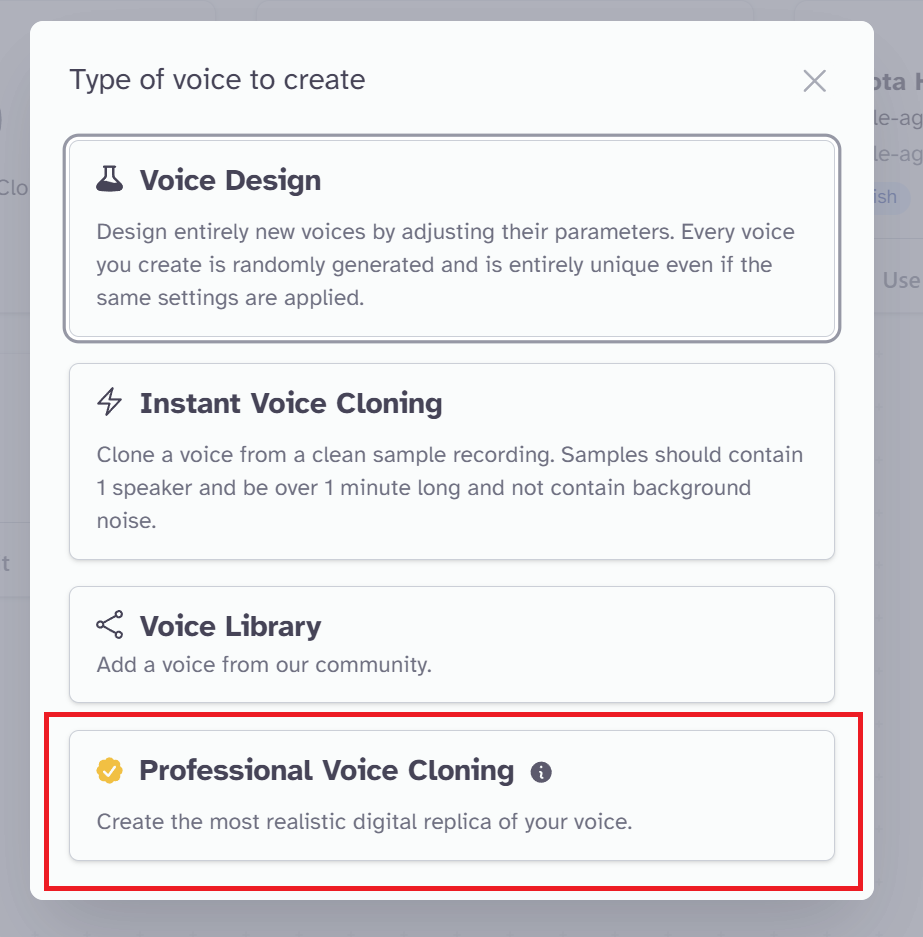
VoiceLabで自分の声から音源作成(Professional Voice Cloning:有料)
さて最後に紹介するのは「Professional Voice Cloning」機能です。
最低”Creater”以上のプランに加入が必要です。
Instantよりも性能が良いと想定します。準備する音声も「30分~3時間の十分な長さの音声ファイル」必要とのことでした。
さっそく機能にアクセスしましょう。「Voice Lab」の「+」マークから「Professional Voice Cloning」を選択します。
すると長い英文が表示されました。注意事項だったり利用手順が書いてあるようです。
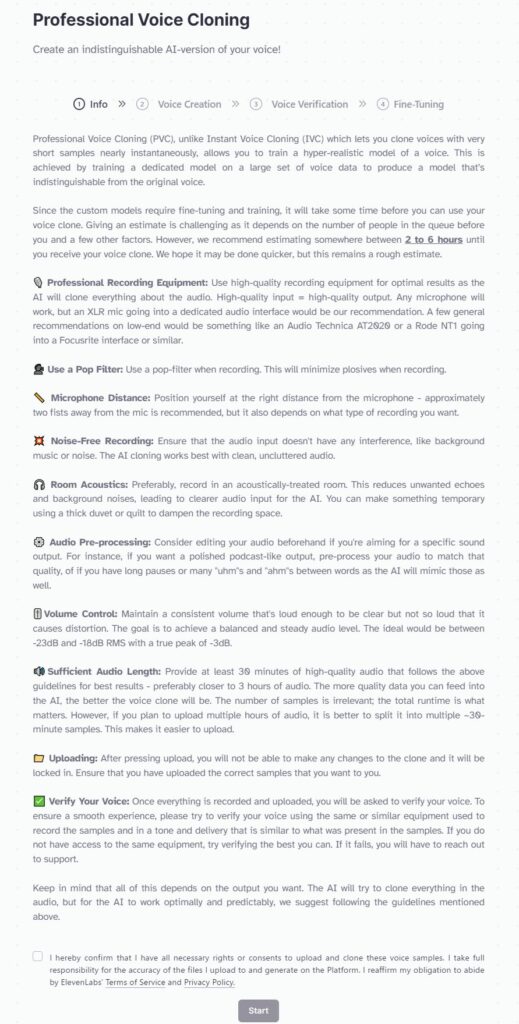
Google翻訳版も掲載しておきます。

次の画面に進むと、音声ファイルのアップロード画面に遷移します。
言語では「Japanese」も選択できますね。
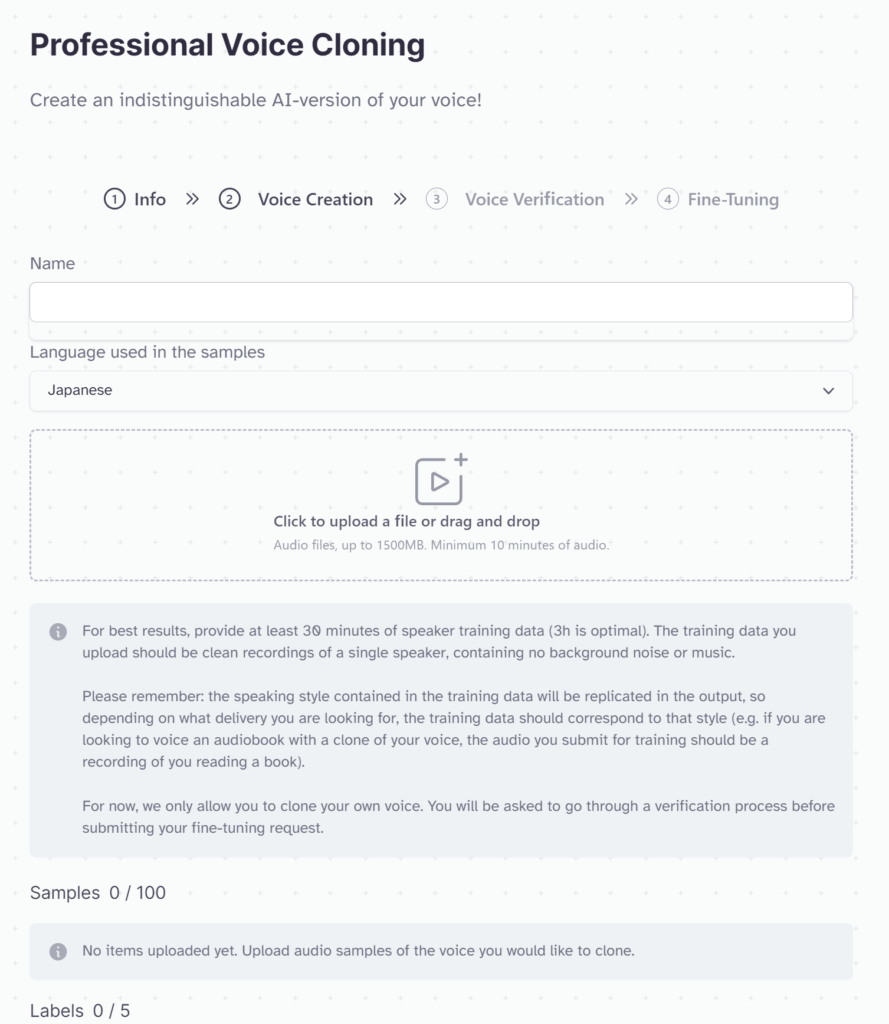
ここでは、長時間の音声ファイルを準備することに時間を要するため割愛します。
音源が生成された後は、Speech機能を活用してスピーチを生成しましょう。
【Project】プロジェクト機能でオーディオブックを作成する
Project機能を使えば簡単にオーディオブックを作成することができます。
Project機能は以下の記事で解説していますので興味のある方はぜひご参考としてください。

【Dubbing】ダビング機能で多言語アウトプット
llElevenLabsのダビング機能は、音声やビデオコンテンツを世界中でアクセス可能にするために、元の声の特徴を保ちながら様々な言語に翻訳・ダビングすることを可能にします。
この機能は特に、教育コンテンツ、プロモーション素材、映画やテレビ番組など、多岐にわたる用途に役立ちます。
多言語対応・複数話者も識別
Dubbing機能は、日本語をはじめとした29言語に対応しており、中国語、韓国語、オランダ語、トルコ語、スウェーデン語など多数の言語でコンテンツのダビングが可能です。
また、転写、翻訳、タイミングなどを細かく制御できる機能を提供し、プロジェクトごとに声の安定性、類似性、スタイルを調整することができます。
複数の話者がいるオーディオやビデオファイルでも、それぞれの声を区別して、翻訳版で個々の声を明確に保つことができます。
Dubbing機能を使ってみる
Dubbing機能はメニューの「Dubbing」を選択します。
サンプルでDubbing機能を利用してみます。
「Source Launguage」には”日本語“、「Target Launguage」では複数言語を選択できますが1言語が推奨のようです。
「Create a Dubbing Studio project」にはチェックを入れ、「Add watermark to reduce charactre usage by 50%」はチェックを外します。
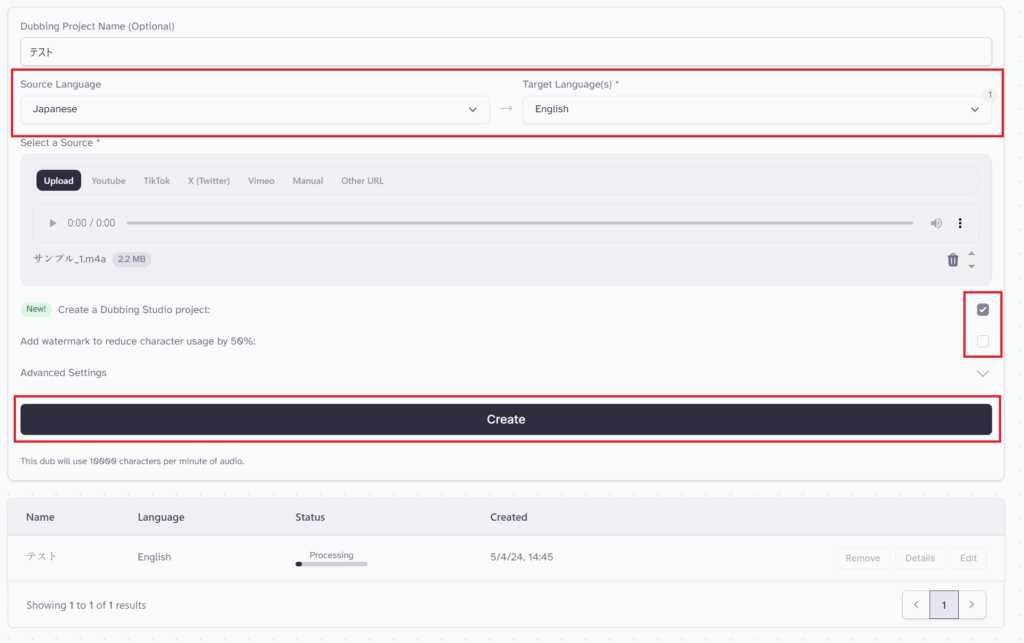
下にDubbingの結果が表示されます。「Edit」ボタンを押します。

編集画面に移動します。はじめはオリジナルソースが表示されます。
音声からしっかりとテキストを認識して、オーディオを入力してくれています。
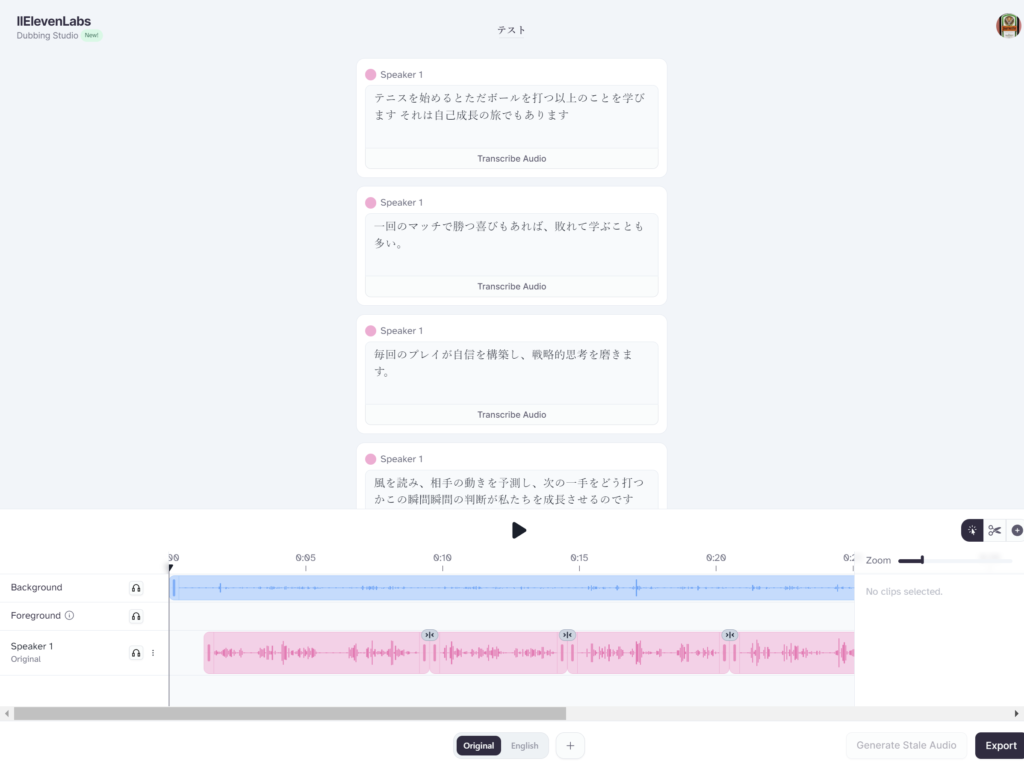
下にある「English」を選択します。(他の言語を選択した場合は、その言語が選択できます)
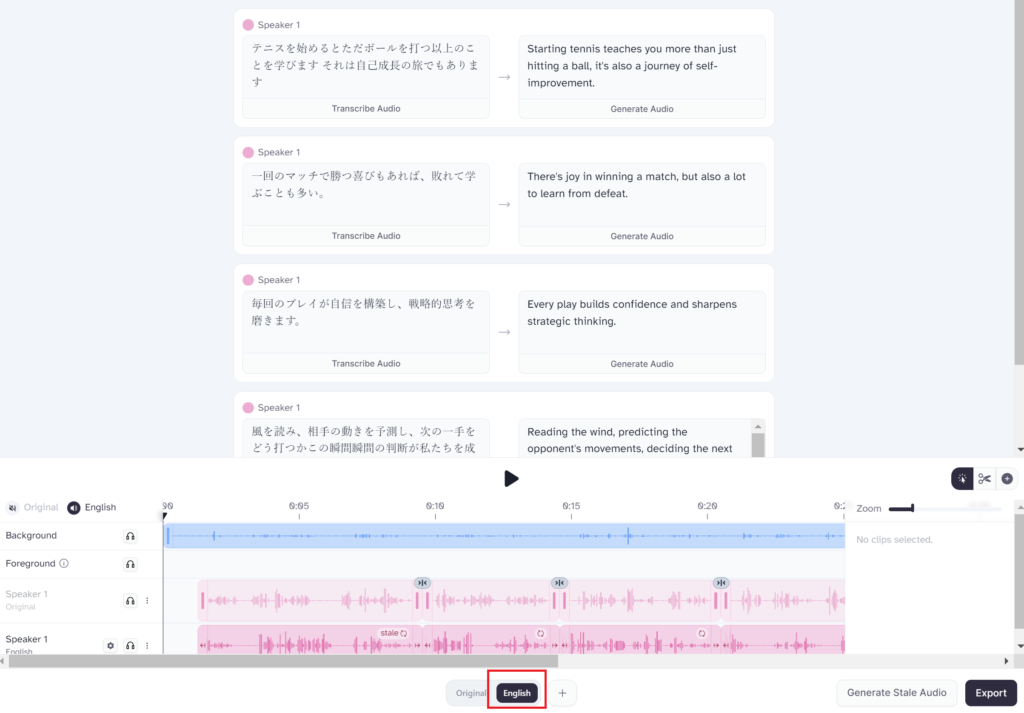
すると英語が表示され、「再生」ボタンを押すと英語で発音されます。
右下の「Export」ボタンを押すと音声ファイルをダウンロードできます。
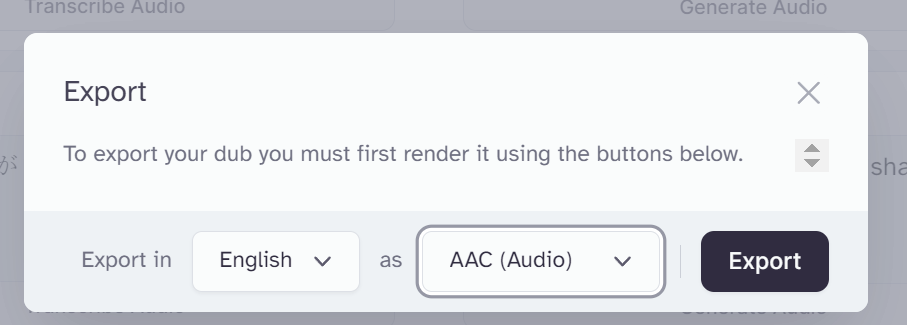
AACファイルでダウンロードができますので、拡張子を変えたい場合は変換しましょう。
(日本語から英語に変換したサンプル音声です)
実践的な使用例
特定の音声情報をもとに声の音源を作成し、それを綺麗に読み上げることができれば、たくさんのコンテンツ生成に役立つでしょう。
ここでは想定される実践的な使用例について紹介します。
オーディオブックの制作

これまでオーディオブックは声優さん録音を繰り返して作成されていたと思います。
しかし、自然な音声でテキストを読み上げることにより、コンテンツの魅力を高めることができれば、楽にクオリティの高いオーディオブックの作成ができます。
間合いやトーンの変化、感情を込めるといったことはAIで完全に制御できるかは未知ですので、このあたりがオーディオブック作成の勘所になるでしょう。
そのほかにもビデオナレーションも音声生成AIで代替されていくでしょう。
eラーニングと教育コンテンツ

特に効果がありそうなのがeラーニングや教育コンテンツですね。
企業では様々な教育を行いますが、教育コンテンツとなると以外に作ることに労力が必要です。
とくに「話す」行為を伴う教育コンテンツは、講師の準備がとても大変ですので、教育コンテンツは今後音声生成AIに置き換わっていくことでしょう。
カスタマーサービスオートメーション
その他に考えられる音声に関連するサービス
その他にも以下のような音声サービスが置き換わることが予想されます。
- 自動応答システムへの音声適用
- 外国語学習支援
- 視覚障碍者支援
- 公共放送やアナウンス
- ゲームなどのエンターテインメント
これまではロボットのようなAI音声だったのが、かなり自然に近い音声になると音声にまつわる仕事が置き換わっていくでしょう。
英語で開発されているので英語の発音はものすごく自然だと思われます。
しかしその内、日本語ももっともっと自然になるでしょう。
llElevenLabsの料金プラン
llElevenLabsは無料でも十分優れたサービスですが、自分が取り入れたい音声を使える点では有料プランが望ましいでしょう。
いかがllElevenLabsのプランの一覧です。
| プラン | Free | Starter | Creator | Independent Publisher | Growing Business | Enterprise |
|---|---|---|---|---|---|---|
| 料金(月額) | 無料 | $5 | $22 ※1 | $99 | $330 | 要相談 |
| 音声生成数(月) | 10,000文字 | 30,000文字 | 100,000文字 | 500,000文字 | 2,000,000文字 | 要相談 |
| AIクローンの数 | 3個 | 10個 | 30個 | 150個 | 660個 | 要相談 |
| Instant Clone | – | 〇 | 〇 | 〇 | 〇 | 〇 |
| Professional Clone | – | – | 〇 | 〇 | 〇 | 〇 |
| 商用利用 | クレジット | 〇 | 〇 | 〇 | 〇 | 〇 |
上記のとおりInstant Cloning機能を利用したい場合は「Starter」プラン~
Professional Clone機能を利用したい場合は「Creator」プラン~を利用する必要があります。
製品の詳細なヘルプについてはこちら(https://help.elevenlabs.io/hc/en-us/articles/13298164480913-What-s-the-maximum-amount-of-characters-and-text-I-can-generate)のサイトを参照ください。
まとめ
llElevenLabsの使い方についてのこのガイドを通じて、テキストから音声への変換技術がどれほど強力で多様な用途に役立つかを理解いただけたかと思います。
llElevenLabsは、直感的なインターフェースと多言語サポートにより、ビジネスプレゼンテーションからエンターテイメント、教育コンテンツまで、あらゆる種類のメディアを瞬時に音声変換、多言語化することが可能です。
今回紹介した具体的なステップとヒントを活用して、あなたのプロジェクトにllElevenLabsを効果的に取り入れ、ビジネス革命のきっかけにしていきましょう。